环境前提
Anaconda是一个用于科学计算的Python发行版,支持Linux,Mac,Windows系统,提供了包管理与环境管理的功能,可以很方便地解决多版本python并存,切换以及各种第三方包安装问题
anaconda利用工具/命令conda来进行package和environment的管理,并且已经包含了Python和相关的配套工具
概念
Anaconda是一个打包的集合,预装了conda,某个版本的python,很多package,科学计算工具等,称为一个发行版
conda是一个工具,也是一个可执行命令,核心功能是包管理和环境管理。包管理与pip的使用类似,环境管理则允许用户方便地安装不同版本的python并可以快速切换
Miniconda是一个简单包,只包含最基本的内容,python和conda,以及相关的必须依赖项
基础语法
- 交互式编程
- 交互式编程不需要创建脚本文件,是通过Python解释器的交互模式来编写代码
- 脚本式编程
- 通过脚本参数调用解释器开始执行脚本,知道脚本执行完毕。当脚本执行完成后,解释器不再有效
标识符
英文字母、数字、下划线组成,不能以数字开头
区分大小写
以下划线开头的标识符是有特殊意义的
Python可以同一行显示多条语句,方法是用分号;分开,如
1 | print("hello");print("Tsinghua"); |
保留字
1 | import keyword |
查看当前系统的关键字
| and | exec | not |
|---|---|---|
| assert | finally | or |
| break | for | pass |
| class | from | |
| continue | global | raise |
| def | if | return |
| del | import | try |
| elif | in | while |
| else | is | with |
| except | lambda | yield |
行和缩进
用缩进来写模块
缩进的空白数量是可变的,但是所有代码快语句必须包含相同的缩进空白数量
Indentation Error: unindent does not match any outer indentation level
引号和注释
可以用引号(’)、双引号( “ )、三引号( ‘’’ 或 “”” ) 来表示字符串,引号的开始与结束须是相同类型
单行注释采用 # 开头。多行注释使用三个单引号 ‘’’ 或三个双引号 “””
函数之间或类的方法之间用空行分隔,表示一段新的代码的开始。类和函数入口之间也用一行空行分隔,以突出函数入口的开始。空行与代码缩进不同,空行并不是Python语法的一部分
print输出
print默认输出是换行的
可以在 print() 函数中添加 end=”” 参数,这样就可以实现不换行效果
参数 end 默认值为 “\n”,即end=”\n”,表示换行,给 end 赋值为空, 即end=””,就不会换行了
变量类型
变量赋值不需要类型声明。
每个变量在内存中创建,都包括变量的标识,名称和数据这些信息
每个变量在使用前都必须赋值,变量赋值以后该变量才会被创建
等号 = 用来给变量赋值
等号 = 运算符左边是一个变量名,等号 = 运算符右边是存储在变量中的值
1 | a=b=c=1 |
五个标准数据类型
- Numbers(数字)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
数字
数字数据类型用于存储数值
他们是不可改变的数据类型,这意味着改变数字数据类型会分配一个新的对象。
当你指定一个值时,Number 对象就会被创建
1 | var1 = 1 |
可以使用del语句删除一些对象的引用
1 | del var |
Python支持四种不同的数字类型:
- int(有符号整型)
- long(长整型, Python3.X 版本中 long 类型被移除,使用 int 替代)
- float(浮点型)
- complex(复数)
- 复数由实数部分和虚数部分构成,可以用 a+bj,或者 complex(a,b) 表示, 复数的实部 a 和虚部 b 都是浮点型
字符串
字符串或串(String)是由数字、字母、下划线组成的一串字符,它是编程语言中表示文本的数据类型
Python的字串列表有2种取值顺序:
- 从左到右索引默认0开始的,最大范围是字符串长度少1
- 从右到左索引默认-1开始的,最大范围是字符串开头

实现从字符串中获取一段子字符串的话,可以使用 [头下标:尾下标] 来截取相应的字符串,其中下标是从 0 开始算起,可以是正数或负数,下标可以为空表示取到头或尾。[头下标:尾下标] 获取的子字符串包含头下标的字符,但不包含尾下标的字符
1 | s = 'abcdef' |
列表
List(列表) 是 Python 中使用最高频的数据类型
列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)
列表用 [] 标识,是 Python 最通用的复合数据类型
列表中值的切割也可以用到变量 [头下标:尾下标] ,就可以截取相应的列表,从左到右索引默认 0 开始,从右到左索引默认 -1 开始,下标可以为空表示取到头或尾
列表截取可以接收第三个参数,参数作用是截取的步长,以下实例在索引 1 到索引 4 的位置并设置
步长为 2(间隔一个位置)来截取字符串
1 | letters = ['c','h','e','c','k','i','o'] |
元组
元组是另一个数据类型,类似于 List(列表)
元组用 () 标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表
1 | tuple = ('tsinghua', 786, 2.23, 'john', 70.2) |
字典
字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象集合,
字典是无序的对象集合
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取
字典用”{ }”标识。字典由索引(key)和它对应的值value组成
1 | dict = {} |
数据类型转换
| 函数 | 描述 |
|---|---|
| int(x [,base]) | 将x转换为一个整数 |
| long(x [,base] ) | 将x转换为一个长整数 |
| float(x) | 将x转换到一个浮点数 |
| complex(real [,imag]) | 创建一个复数 |
| str(x) | 将对象 x 转换为字符串 |
| >repr(x) | 将对象 x 转换为表达式字符串 |
| eval(str) | 用来计算在字符串中的有效Python表达式,并返回一个对象 |
| tuple(s) | 将序列 s 转换为一个元组 |
| list(s) | 将序列 s 转换为一个列表 |
| set(s) | 转换为可变集合 |
| dict(d) | 创建一个字典。d 必须是一个序列 (key,value)元组。 |
| frozenset(s) | 转换为不可变集合 |
| chr(x) | 将一个整数转换为一个字符 |
| unichr(x) | 将一个整数转换为Unicode字符 |
| ord(x) | 将一个字符转换为它的整数值 |
| hex(x) | 将一个整数转换为一个十六进制字符串 |
| oct(x) | 将一个整数转换为一个八进制字符串 |
运算符
赋值、比较、赋值运算符
a = 10, b = 20
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 - 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘 - 两个数相乘或是返回一个被重复若干次的字符串 | a * b 输出结果 200 |
| / | 除 - x除以y | b / a 输出结果 2 |
| % | 取模 - 返回除法的余数 | b % a 输出结果 0 |
| ** | 幂 - 返回x的y次幂 | a**b 为10的20次方, 输出结果100000000000000000000 |
| // | 取整除 - 返回商的整数部分(向下取整) | >>> 9//2 4 >>> -9//2 -5 |
| == | 等于 - 比较对象是否相等 | (a == b) 返回 False |
| != | 不等于 - 比较两个对象是否不相等 | (a != b) 返回 True |
| <> | 不等于 - 比较两个对象是否不相等。python3 已废弃 | (a <> b) 返回 True。这个运算符类似 != |
| > | 大于 - 返回x是否大于y | (a > b) 返回 False |
| < | 小于 - 返回x是否小于y | (a < b) 返回 True |
| >= | 大于等于 - 返回x是否大于等于y | (a >= b) 返回 False |
| <= | 小于等于 - 返回x是否小于等于y | (a <= b) 返回 True |
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
位运算符
- &
- 按位与运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0
- |
- 按位或运算符:只要对应的二个二进位有一个为1时,结果位就为1
- ^
- 按位异或运算符:当两对应的二进位相异时,结果为1
- ~
- 按位取反运算符:对数据的每个二进制位取反,即把1变为0,把0变为1 。~x 类似于 -x-1
- <<
- 左移动运算符:运算数的各二进位全部左移若干位,由 << 右边的数字指定了移动的位数,高位丢弃,低位补0
- 60 << 2为240
- >>
- 右移动运算符:把”>>”左边的运算数的各二进位全部右移若干位,>> 右边的数字指定了移动的位数
逻辑运算符
a = 10, b = 20
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔”与” - 如果 x 为 False,x and y 返回False,否则它返回 y 的计算值 | (a and b) 返回 20 |
| or | x or y | 布尔”或” - 如果 x 是非 0,它返回 x 的计算值,否则它返回 y 的计算值 | (a or b) 返回 10 |
| not | not x | 布尔”非” - 如果 x 为 True,返回 False 。如果 x 为 False,它返回 True | not(a and b) 返回 False |
成员运算符
- in
- 如果在指定的序列中找到值返回 True,否则返回 False
- not in
- 如果在指定的序列中没有找到值返回 True,否则返回 False
1 | #!/usr/bin/python |
身份运算符
- is
- is 是判断两个标识符是不是引用自一个对象
- is not
- is not 是判断两个标识符是不是引用自不同对象
1 | a = [1, 2, 3] |
is 与 == 区别:
is 用于判断两个变量引用对象是否为同一个(同一块内存空间), == 用于判断引用变量的值是否相等
运算符优先级
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~+- | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,除,取模和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not and or | 逻辑运算符 |
程序控制结构
条件语句
1 | if 判断条件: |
1 | if 判断条件1: |
循环语句
while、for
1 | while []: |
else 中的语句会在循环正常执行完
break
- 在语句块执行中终止循环,并且跳出整个循环
continue
- 在语句块执行过程中终止当前循环,跳出该次循环
pass
- 空语句,为了保持程序结构的完整性
range()
如果你需要遍历数字序列,可以使用内置range()函数。它会生成数列,例如:
1 | for i in range(5): print(i) |
可以结合range()和len()函数以遍历一个序列的索引,如下所示:
1 | a = ['Google', 'Baidu', 'Bing', 'Taobao', 'QQ'] |
还可以使用range()函数来创建一个列表:
1 | list(range(5)) |
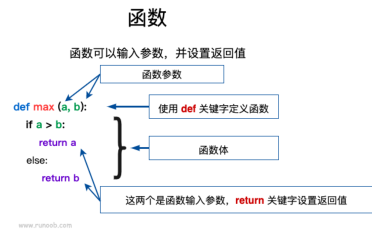
函数
定义一个函数:可定义一个由自己想要功能的函数,以下是简单的规则:
- 函数代码块以 def 关键词开头,后接函数标识符名称和圆括号()
- 任何传入参数和自变量必须放在圆括号中间。圆括号之间可以用于定义参数
- 函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明
- 函数内容以冒号起始,并且缩进
- return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None
1 | def functionname( parameters ): |
参数传递
Python 中,类型属于对象,变量没有类型
1 | a = [1, 2, 3] |
[1,2,3] 是 List 类型,“Tsinghua” 是 String 类型,而变量 a 是没有类型,它仅仅是一个对象的引用(一个指针),可以是 List 类型对象,也可以指向String 类型对象
在 Python 中,strings, tuples, 和 numbers是不可更改的对象,而 list, dict 等则是可以修改的对象
- 不可变类型:变量赋值 a=5 后再赋值 a=10,这里实际是新生成一个 int 值对象 10,再让 a 指向它,而 5 被丢弃,不是改变a的值,相当于新生成了a
- 可变类型:变量赋值 la=[1,2,3,4] 后再赋值 la[2]=5 则是将 list la 的第三个元素值更改,本身la没有动,只是其内部的一部分值被修改了
参数类型
以下是调用函数时可使用的正式参数类型:
必备参数
- 必备参数须以正确的顺序传入函数。调用时的数量必须和声明时的一样
关键字参数
默认参数
- 调用函数时,默认参数的值如果没有传入,则被认为是默认值
不定长参数
- 需要一个函数能处理比当初声明时更多的参数。这些参数叫做不定长参数,和上述参数不同,声明时不会命名
匿名函数
使用 lambda 来创建匿名函数
所谓匿名,意即不再使用 def 语句这样标准的形式定义一个函数
lambda 只是一个表达式,函数体比 def 简单很多。主体是一个表达式,而不是一个代码块。仅仅能在 lambda 表达式中封装有限的逻辑进去。lambda 函数拥有自己的命名空间,且不能访问自己参数列表之外或全局命名空间里的参数
1 | lambda [arg1 [,arg2,.....argn]]:expression |
可将匿名函数封装在一个函数内,这样可以使用同样的代码来创建多个匿名函数。
以下实例将匿名函数封装在 myfunc 函数中,通过传入不同的参数来创建不同的匿名函数
1 | def myfunc(n): |
return [表达式] 语句用于退出函数,选择性地向调用方返回一个表达式。不带参数值的 return 语句返回 None
PYTHON面向对象
基础概念
- 类(Class)
- 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例
- 方法
- 类中定义的函数
- 类变量
- 类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用
- 数据成员
- 类变量或者实例变量用于处理类及其实例对象的相关的数据
- 方法重写
- 如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写
- 局部变量
- 定义在方法中的变量,只作用于当前实例的类
- 实例变量
- 在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self修饰的变量
- 继承
- 即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待
- 实例化
- 创建一个类的实例,类的具体对象
- 对象
- 通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法
类对象
类对象支持两种操作:属性引用和实例化
属性引用使用和 Python 中所有的属性引用一样的标准语法:obj.name
类对象创建后,类命名空间中所有的命名都是有效属性名
1 | class ClassName |
类有一个名为 _init_() 的特殊方法(构造方法),该方法在类实例化时会自动调用
1 | def __init__(self): |
类的方法与普通的函数只有一个特别的区别——它们必须有一个额外的第一个参数名称, 按照惯例它的名称是 self
self代表的是类的实例,代表当前对象的地址,而self.class则指向类
类的继承
子类(派生类 DerivedClassName)会继承父类(基类 BaseClassName)的属性和方法。
BaseClassName(实例中的基类名)必须与派生类定义在一个作用域内
1 | # !/usr/bin/python3 |
类的属性与方法
类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs
类的私有方法
__init__ : 构造函数,在生成对象时调用
__del__ : 析构函数,释放对象时使用
__repr__ : 打印,转换
__setitem__ : 按照索引赋值
__getitem__: 按照索引获取值
__len__: 获得长度
__cmp__: 比较运算
__call__: 函数调用
__add__: 加运算
__sub__: 减运算
__mul__: 乘运算
__truediv__: 除运算
__mod__: 求余运算
__pow__: 乘方
运算符重载
1 | class Vector: |
W1 补充
随机数生成
1 | import random |
列表头尾元素对调
1 | def swapList(newList): |
日历\日期
1 | # 引入日历模块 |
秒表
主要是用了try-except的组合
1 | import time |
科学计算
环境
NumPy (Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与
矩阵运算,此外也针对数组运算提供大量的数学函数库
NumPy 通常与 SciPy(Scientific Python)和 Matplotlib(绘图库)一起使用, 这种组合
广泛用于替代 Matlab,是一个强大的科学计算环境,有助于我们通过 Python 学习数据科
学或者机器学习
SciPy 是一个开源的 Python 算法库和数学工具包。SciPy 包含的模块有最优化、线性代数、
积分、插值、特殊函数、快速傅里叶变换、信号处理和图像处理、常微分方程求解和其他科
学与工程中常用的计算
Matplotlib 是 Python 编程语言及其数值数学扩展包 NumPy 的可视化操作界面。它为利
用通用的图形用户界面工具包,如 Tkinter, wxPython, Qt 或 GTK+ 向应用程序嵌入式绘图
提供了应用程序接口(API)
NUMPY
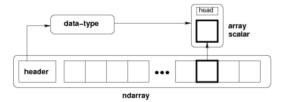
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引
ndarray 对象是用于存放同类型元素的多维数组。ndarray 中的每个元素在内存中都有相同存储大小的区域。ndarray 内部由以下内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针
- 数据类型或 dtype,描述在数组中的固定大小值的格子
- 一个表示数组形状(shape)的元组,表示各维度大小的元组
- 一个跨度元组(stride),其中的整数指的是为了前进到当前维度下一个元素需要”跨过”的字节数
ndarray 的内部结构:
数组类
NumPy的数组类被调用ndarray。它也被别名所知 array。请注意,numpy.array这与标准Python库类不同array.array,后者只处理一维数组并提供较少的功能。ndarray对象更重要的属性是:
- ndarray.ndim - 数组的轴(维度)的个数。在Python世界中,维度的数量被称为rank
- ndarray.shape - 数组的维度。这是一个整数的元组,表示每个维度中数组的大小。对于有 n 行和 m 列的矩阵,shape 将是 (n,m)。因此,shape 元组的长度就是rank或维度的个数 ndim
- ndarray.size - 数组元素的总数。这等于 shape 的元素的乘积
- ndarray.dtype - 一个描述数组中元素类型的对象。可以使用标准的Python类型创建或指定dtype。另外NumPy提供它自己的类型。例如numpy.int32、numpy.int16和numpy.float64
- ndarray.itemsize - 数组中每个元素的字节大小。例如,元素为 float64 类型的数组的 itemsize 为8(=64/8),而 complex32 类型的数组的 itemsize 为4(=32/8)。它等于 ndarray.dtype.itemsize
创建
1 | numpy.arry(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0) |
| 名称 | 描述 |
|---|---|
| object | 数组或嵌套的数列 |
| dtype | 数组元素的数据类型,可选 |
| copy | 对象是否需要复制,可选 |
| order | 创建数组的样式,C为行方向,F为列方向,A为任意方向(默认) |
| subok | 默认返回一个与基类类型一致的数组 |
| ndmin | 指定生成数组的最小维度 |
1 | import numpy as np |
可以使用array函数从常规Python列表或元组中创建数组。得到的数组的类型是从Python列表中元素的类型推导出来的
array 还可以将序列的序列转换成二维数组、三维数组等,也可以在创建时显式指定数组的类型
通常,数组的元素最初是未知的,但它的大小是已知的。因此,NumPy提供了几个函数来创建具有初始占位符内容的数组
1 | #生成3行4列零矩阵 |
为了创建数字组成的数组,NumPy提供了一个类似于range的函数,该函数返回数组而不是列表
1 | np.arange(10,30,5) |
当arange与浮点参数一起使用时,由于有限的浮点精度,通常不可能预测所获得的元素的数量。出于这个原因,通常最好使用linspace函数来接收我们想要的元素数量的函数,而不是步长(step)
1 | from numpy import pi |
索引、切片
一维的数组可以进行索引、切片和迭代操作的,就像列表和其他Python序列类型一样
多维的数组每个轴可以有一个索引。这些索引以逗号分隔的元组给出
1 | b[2,3] |
迭代
对多维数组进行 迭代(Iterating) 是相对于第一个轴完成的
如果想要对数组中的每个元素执行操作,可以使用flat属性,该属性是数组的所有元素的迭代
1 | for row in b: |
数据类型
不附表
数学函数
NumPy提供熟悉的数学函数,例如sin,cos和exp。在NumPy中,这些被称为“通函数”(ufunc)。在NumPy中,这些函数在数组上按元素进行运算,产生一个数组作为输出
舍入函数
2
numpy.around(a,decimals)参数说明:
•a: 数组
•decimals: 舍入的小数位数。 默认值为0。 如果为负,整数将四舍五入到小数点左侧的位置
算数函数
NumPy 算术函数包含简单的加减乘除: add(),subtract(),multiply() 和 divide()。需要注意的是数组必须具有相同的形状或符合数组广播规则
numpy.reciprocal() 函数返回参数逐元素的倒数。如 1/4 倒数为 4/1
矩阵运算
1 | import numpy as np |
与许多矩阵语言不同,乘积运算符*在NumPy数组中按元素进行运算。矩阵乘积可以使用@运算符(在python> = 3.5中)或dot函数或方法执行
1 | A = np.array([[1,1],[0,1]]) |
Broadcast 广播
广播(Broadcast)是 numpy 对不同形状(shape)的数组进行数值计算的方式, 对数组的算术运算通常在相应的元素上进行
如果两个数组 a 和 b 形状相同,即满足 a.shape == b.shape,那么 a*b 的结果就是 a 与 b 数组对应位相乘。这要求维数相同,且各维度的长度相同
4x3 的二维数组与长为 3 的一维数组相加,等效于把数组 b 在二维上重复 4 次再运算
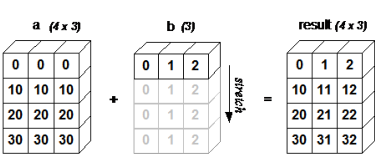
广播的规则:
- 让所有输入数组都向其中形状最长的数组看齐,形状中不足的部分都通过在前面加 1 补齐
- 输出数组的形状是输入数组形状的各个维度上的最大值
- 如果输入数组的某个维度和输出数组的对应维度的长度相同或者其长度为 1 时,这个数组能够用来计算,否则出错
- 当输入数组的某个维度的长度为 1 时,沿着此维度运算时都用此维度上的第一组值
简单理解:对两个数组,分别比较他们的每一个维度(若其中一个数组没有当前维度则忽略),满足:
- 数组拥有相同形状
- 当前维度的值相等
- 当前维度的值有一个是 1
若条件不满足,抛出 “ValueError: frames are not aligned” 异常
SCIPY
https://wizardforcel.gitbooks.io/scipy-lecture-notes/content/index.html
模块列表
不附表
常量模块
不附表
Optimize
NumPy 能够找到多项式和线性方程的根,但它无法找到非线性方程的根
我们可以使用 SciPy 的 optimze.root函数,这个函数需要两个参数:
- fun - 表示方程的函数
- x0 - 根的初始猜测
1 | from scipy.optimize import root |
最小化
可以使用 scipy.optimize.minimize() 函数来最小化函数
minimize() 函接受以下几个参数:
- fun - 要优化的函数
- x0 - 初始猜测值
- method - 要使用的方法名称,值可以是:’CG’,’BFGS’,’Newton-CG’,’L-BFGS-B’,’TNC’,’COBYLA’,’SLSQP’
- callback - 每次优化迭代后调用的函数
- options - 定义其他参数的字典
实例:$x^2+x+2$使用BFGS的最小化函数
1 | from scipy.optimize import minimize |
Scipy稀疏矩阵
稀疏矩阵(英语:sparse matrix)指的是在数值分析中绝大多数数值为零的矩阵。反之,如果大部分元素都非零,则这个矩阵是稠密的(Dense)
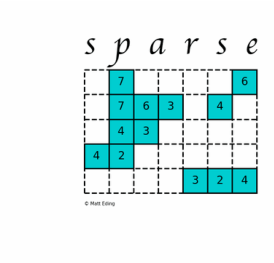
在科学与工程领域中求解线性模型时经常出现大型的稀疏矩阵
SciPy 的 scipy.sparse 模块提供了处理稀疏矩阵的函数
我们主要使用以下两种类型的稀疏矩阵:
- CSC - 压缩稀疏列(Compressed Sparse Column),按列压缩
- CSR - 压缩稀疏行(Compressed Sparse Row),按行压缩
1 | import numpy as np |
使用count_nonzero()方法计算非0元素总数
1 | arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]]) |
使用eliminate_zeros()方法删除矩阵中0元素
1 | arr = np.array([[0, 0, 0], [0, 0, 1], [1, 0, 2]]) |
插值
在数学的数值分析领域中,插值(英语:interpolation)是一种通过已知的、离散的数据点,
在范围内推求新数据点的过程或方法
简单来说插值是一种在给定的点之间生成点的方法
插值有很多用途,在机器学习中我们经常处理数据缺失的数据,插值通常可用于替换这些值。这种填充值的方法称为插补
SciPy 提供了 scipy.interpolate 模块来处理插值
一维数据的插值运算可以通过方法 interp1d() 完成。该方法接收两个参数 x 点和 y 点。返回值是可调用函数,该函数可以用新的 x 调用并返回相应的 y,y = f(x)
interp1d的method指定插值类型,默认是method=linear一次函数f(x)=ax+b线性插值
1 | from scipy.interpolate import interp1d |
单变量插值
在一维插值中,点是针对单个曲线拟合的,而在样条插值中,点是针对使用多项式分段定义的函数拟合的
单变量插值使用 UnivariateSpline() 函数,该函数接受 xs 和 ys 并生成一个可调用函数,该函数可以用新的 xs 调用
为非线性点找到 2.1、2.2…2.9 的单变量样条插值
1 | from scipy.interpolate import UnivariateSpline |
径向基函数插值
径向基函数是对应于固定参考点定义的函数
曲面插值里我们一般使用径向基函数插值
Rbf() 函数接受 xs 和 ys 作为参数,并生成一个可调用函数,该函数可以用新的 xs 调用
为非线性点找到 2.1、2.2…2.9 的径向基函数插值
1 | from scipy.interpolate import Rbf |
显著性检验
显著性检验(significance test)就是事先对总体(随机变量)的参数或总体分布形式做出一个假设,然后利用样本信息来判断这个假设(备择假设)是否合理,即判断总体的真实情况与原假设是否有显著性差异
显著性检验即用于实验处理组与对照组或两种不同处理的效应之间是否有差异,以及这种差异是
否显著的方法
SciPy 提供了 scipy.stats 的模块来执行Scipy 显著性检验的功能
normaltest() 函数返回零假设的 p 值,查找数据是否来自正态分布
1 | import numpy as np |
正态性检验(偏度和峰度)
利用观测数据判断总体是否服从正态分布的检验称为正态性检验,它是统计判决中重要的一种特殊的拟合优度假设检验
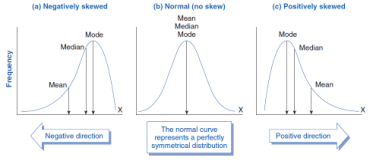
偏度
数据对称性的度量
对于正态分布,它是 0
如果为负,则表示数据向左倾斜
如果为正,则表示数据向右倾斜
![]()
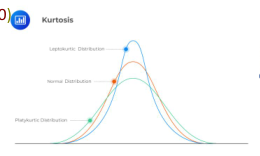
峰度
衡量数据是重尾还是轻尾正态分布的度量
正峰度意味着重尾
负峰度意味着轻尾
![]()
正态性检验基于偏度和峰度。查找数组中值的偏度和峰度
1 | import numpy as np |
MATPLOTLIB
https://matplotlib.org/stable/tutorials/index.html
pylab
pylab 是 matplotlib 面向对象绘图库的一个接口。它的语法和 Matlab 十分相近。主要的绘图命令和 Matlab 对应的命令有相似的参数
基本作图
1 | import numpy as np |
1 | from pylab import * |
设置记号
设置记号的时候,我们可以同时设置记号的标签。注意这里使用了 LaTeX
1 | xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi], [r'$-\pi$', r'$-\pi/2$',r'$0$', r'$+\pi/2$', r'$+\pi$']) |
移动脊柱
坐标轴线和上面的记号连在一起就形成了脊柱(Spines,一条线段上有一系列的凸起,很像脊柱骨),它记录了数据区域的范围。它们可以放在任意位置,不过至今为止,我们都把它放在图的四边
实际上每幅图有四条脊柱(上下左右),为了将脊柱放在图的中间,我们必须将其中的两条(上和右)
设置为无色,然后调整剩下的两条到合适的位置——数据空间的 0 点
1 | ax = gca() |
添加图例、注释
在图的左上角添加一个图例。只需要在 plot 函数里以「键 - 值」的形式增加一个参数
1 | plot(X, C, color="blue", linewidth=2.5,linestyle="-", label="cosine") |
我们希望在 2π/3 的位置给两条函数曲线加上一个注释。首先,我们在对应的函数图像位置上画一个点;然后,向横轴引一条垂线,以虚线标记;最后,写上标签
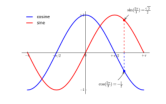
子图
可以显式地控制图像、子图、坐标轴
Matplotlib 中的「图像」指的是用户界面看到的整个窗口内容。在图像里面有所谓「子图」。子图的位置是由坐标网格确定的,而「坐标轴」却不受此限制,可以放在图像的任意位置。我们已经隐式地使用过图像和子图:当我们调用 plot 函数的时候,matplotlib 调用 gca() 函数以及 gcf() 函数来获取当前的坐标轴和图像;如果无法获取图像,则会调用 figure() 函数来创建一个——严格地说,是用 subplot(1,1,1)创建一个只有一个子图的图像
示例一
1 | from pylab import * |
示例二
1 | import matplotlib.pyplot as plt |
散点图、条形图和极轴图
1 | # scatter |
改变坐标轴
1 | import numpy as np |
配色
1 | import numpy as np |

更多示例
https://www.python-graph-gallery.com/
前端作图界面
https://echarts.apache.org/en/index.html
PANDAS
Pandas 是 Python 语言的一个扩展程序库,用于数据分析
1 | import pandas as pd |
数据类型
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型
Series 由索引(index)和列组成
1 | pandas.Series( data, index, dtype, name, copy) |
参数说明:
- data:一组数据(ndarray 类型)
- index:数据索引标签,如果不指定,默认从 0 开始
- dtype:数据类型,默认会自己判断
- name:设置名称
- copy:拷贝数据,默认为 False
1 | import pandas as pd |
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)
DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)
1 | pandas.DataFrame( data, index, columns, dtype, copy) |
参数说明:
data:一组数据(ndarray、series, map, lists, dict 等类型)
index:索引值,或者可以称为行标签
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n)
dtype:数据类型
copy:拷贝数据,默认为 False
1 | import pandas as pd |
CSV
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用
Pandas 可以很方便的处理 CSV 文件
1 | import pandas as pd |
- to_string() 用于返回 DataFrame 类型的数据,如果不使用该函数,则输出结果为数据的前面 5 行和末尾 5 行,中间部分以 … 代替
- head( n ) 方法用于读取前面的 n 行,如果不填参数 n ,默认返回 5 行
- tail( n ) 方法用于读取尾部的 n 行,如果不填参数 n ,默认返回 5 行,空行各个字段的值返回 NaN
- info() 方法返回表格的一些基本信息